Algorithm
Definition
In mathematics and computer science, an algorithm (/ˈælɡərɪðəm/ ( listen)) is an unambiguous specification of how to solve a class of problems. Algorithms can perform calculation, data processing and automated reasoning tasks.
listen)) is an unambiguous specification of how to solve a class of problems. Algorithms can perform calculation, data processing and automated reasoning tasks.
As an effective method, an algorithm can be expressed within a finite amount of space and time and in a well-defined formal language for calculating a function. Starting from an initial state and initial input (perhaps empty), the instructions describe a computation that, when executed, proceeds through a finite number of well-defined successive states, eventually producing "output" and terminating at a final ending state. The transition from one state to the next is not necessarily deterministic; some algorithms, known as randomized algorithms, incorporate random input.
The concept of algorithm has existed for centuries and the use of the concept can be ascribed to Greek mathematicians, e.g. the sieve of Eratosthenesand Euclid's algorithm; the term algorithm itself derives from the 9th Century mathematician Muḥammad ibn Mūsā al'Khwārizmī, latinized 'Algoritmi'. A partial formalization of what would become the modern notion of algorithm began with attempts to solve the Entscheidungsproblem (the "decision problem") posed by David Hilbert in 1928. Subsequent formalizations were framed as attempts to define "effective calculability" or "effective method"; those formalizations included the Gödel–Herbrand–Kleene recursive functions of 1930, 1934 and 1935, Alonzo Church's lambda calculus of 1936, Emil Post's Formulation 1 of 1936, and Alan Turing's Turing machines of 1936–7 and 1939.
Etymology
The word 'algorithm' has its roots in latinizing the name of Muhammad ibn Musa al-Khwarizmi in a first step to algorismus. Al-Khwārizmī (Persian: خوارزمی, c. 780–850) was a Persianmathematician, astronomer, geographer, and scholar in the House of Wisdom in Baghdad, whose name means 'the native of Khwarezm', a region that was part of Greater Iran and is now in Uzbekistan.
About 825, al-Khwarizmi wrote an Arabic language treatise on the Hindu–Arabic numeral system, which was translated into Latin during the 12th century under the title Algoritmi de numero Indorum. This title means "Algoritmi on the numbers of the Indians", where "Algoritmi" was the translator's Latinization of Al-Khwarizmi's name. Al-Khwarizmi was the most widely read mathematician in Europe in the late Middle Ages, primarily through another of his books, the Algebra. In late medieval Latin, algorismus, English 'algorism', the corruption of his name, simply meant the "decimal number system". In the 15th century, under the influence of the Greek word ἀριθμός 'number' (cf. 'arithmetic'), the Latin word was altered to algorithmus, and the corresponding English term 'algorithm' is first attested in the 17th century; the modern sense was introduced in the 19th century.
In English, it was first used in about 1230 and then by Chaucer in 1391. English adopted the French term, but it wasn't until the late 19th century that "algorithm" took on the meaning that it has in modern English.
Another early use of the word is from 1240, in a manual titled Carmen de Algorismo composed by Alexandre de Villedieu. It begins thus:
which translates as:
The poem is a few hundred lines long and summarizes the art of calculating with the new style of Indian dice, or Talibus Indorum, or Hindu numerals.
Informal definition
An informal definition could be "a set of rules that precisely defines a sequence of operations." which would include all computer programs, including programs that do not perform numeric calculations. Generally, a program is only an algorithm if it stops eventually.
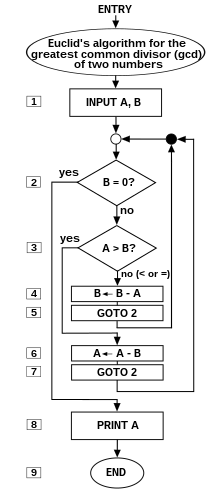
A prototypical example of an algorithm is the Euclidean algorithm to determine the maximum common divisor of two integers; an example (there are others) is described by the flowchartabove and as an example in a later section.
Boolos, Jeffrey & 1974, 1999 offer an informal meaning of the word in the following quotation:
An "enumerably infinite set" is one whose elements can be put into one-to-one correspondence with the integers. Thus, Boolos and Jeffrey are saying that an algorithm implies instructions for a process that "creates" output integers from an arbitrary "input" integer or integers that, in theory, can be arbitrarily large. Thus an algorithm can be an algebraic equation such as y = m + n – two arbitrary "input variables" m and n that produce an output y. But various authors' attempts to define the notion indicate that the word implies much more than this, something on the order of (for the addition example):
- Precise instructions (in language understood by "the computer") for a fast, efficient, "good" process that specifies the "moves" of "the computer" (machine or human, equipped with the necessary internally contained information and capabilities) to find, decode, and then process arbitrary input integers/symbols m and n, symbols + and = ... and "effectively" produce, in a "reasonable" time, output-integer y at a specified place and in a specified format.
The concept of algorithm is also used to define the notion of decidability. That notion is central for explaining how formal systems come into being starting from a small set of axioms and rules. In logic, the time that an algorithm requires to complete cannot be measured, as it is not apparently related with our customary physical dimension. From such uncertainties, that characterize ongoing work, stems the unavailability of a definition of algorithm that suits both concrete (in some sense) and abstract usage of the term.
Formalization
Algorithms are essential to the way computers process data. Many computer programs contain algorithms that detail the specific instructions a computer should perform (in a specific order) to carry out a specified task, such as calculating employees' paychecks or printing students' report cards. Thus, an algorithm can be considered to be any sequence of operations that can be simulated by a Turing-complete system. Authors who assert this thesis include Minsky (1967), Savage (1987) and Gurevich (2000):
Typically, when an algorithm is associated with processing information, data can be read from an input source, written to an output device and stored for further processing. Stored data are regarded as part of the internal state of the entity performing the algorithm. In practice, the state is stored in one or more data structures.
For some such computational process, the algorithm must be rigorously defined: specified in the way it applies in all possible circumstances that could arise. That is, any conditional steps must be systematically dealt with, case-by-case; the criteria for each case must be clear (and computable).
Because an algorithm is a precise list of precise steps, the order of computation is always crucial to the functioning of the algorithm. Instructions are usually assumed to be listed explicitly, and are described as starting "from the top" and going "down to the bottom", an idea that is described more formally by flow of control.
So far, this discussion of the formalization of an algorithm has assumed the premises of imperative programming. This is the most common conception, and it attempts to describe a task in discrete, "mechanical" means. Unique to this conception of formalized algorithms is the assignment operation, setting the value of a variable. It derives from the intuition of "memory" as a scratchpad. There is an example below of such an assignment.
For some alternate conceptions of what constitutes an algorithm see functional programming and logic programming.
Expressing algorithms
Algorithms can be expressed in many kinds of notation, including natural languages, pseudocode, flowcharts, drakon-charts, programming languages or control tables (processed by interpreters). Natural language expressions of algorithms tend to be verbose and ambiguous, and are rarely used for complex or technical algorithms. Pseudocode, flowcharts, drakon-chartsand control tables are structured ways to express algorithms that avoid many of the ambiguities common in natural language statements. Programming languages are primarily intended for expressing algorithms in a form that can be executed by a computer, but are often used as a way to define or document algorithms.
There is a wide variety of representations possible and one can express a given Turing machine program as a sequence of machine tables (see more at finite-state machine, state transition tableand control table), as flowcharts and drakon-charts (see more at state diagram), or as a form of rudimentary machine code or assembly code called "sets of quadruples" (see more at Turing machine).
Representations of algorithms can be classed into three accepted levels of Turing machine description:
- 1 High-level description
- "...prose to describe an algorithm, ignoring the implementation details. At this level we do not need to mention how the machine manages its tape or head."
- 2 Implementation description
- "...prose used to define the way the Turing machine uses its head and the way that it stores data on its tape. At this level we do not give details of states or transition function."
- 3 Formal description
- Most detailed, "lowest level", gives the Turing machine's "state table".
For an example of the simple algorithm "Add m+n" described in all three levels, see Algorithm#Examples.
Design
Algorithm design refers to a method or mathematical process for problem solving and engineering algorithms. The design of algorithms is part of many solution theories of operation research, such as dynamic programming and divide-and-conquer. Techniques for designing and implementing algorithm designs are also called algorithm design patterns, such as the template method pattern and decorator pattern.
One of the most important aspects of algorithm design is creating an algorithm that has an efficient runtime, also known as its Big O.
Typical steps in development of algorithms:
- Problem definition
- Development of a model
- Specification of algorithm
- Designing an algorithm
- Checking the correctness of algorithm
- Analysis of algorithm
- Implementation of algorithm
- Program testing
- Documentation preparation
Implementation
Most algorithms are intended to be implemented as computer programs. However, algorithms are also implemented by other means, such as in a biological neural network (for example, the human brain implementing arithmetic or an insect looking for food), in an electrical circuit, or in a mechanical device.
Computer algorithms
In computer systems, an algorithm is basically an instance of logic written in software by software developers to be effective for the intended "target" computer(s) to produce output from given (perhaps null) input. An optimal algorithm, even running in old hardware, would produce faster results than a non-optimal (higher time complexity) algorithm for the same purpose, running in more efficient hardware; that is why algorithms, like computer hardware, are considered technology.
"Elegant" (compact) programs, "good" (fast) programs : The notion of "simplicity and elegance" appears informally in Knuth and precisely in Chaitin:
- Knuth: "...we want good algorithms in some loosely defined aesthetic sense. One criterion... is the length of time taken to perform the algorithm.... Other criteria are adaptability of the algorithm to computers, its simplicity and elegance, etc"
- Chaitin: "... a program is 'elegant,' by which I mean that it's the smallest possible program for producing the output that it does"
Chaitin prefaces his definition with: "I'll show you can't prove that a program is 'elegant'"—such a proof would solve the Halting problem (ibid).
Algorithm versus function computable by an algorithm: For a given function multiple algorithms may exist. This is true, even without expanding the available instruction set available to the programmer. Rogers observes that "It is... important to distinguish between the notion of algorithm, i.e. procedure and the notion of function computable by algorithm, i.e. mapping yielded by procedure. The same function may have several different algorithms".
Unfortunately there may be a tradeoff between goodness (speed) and elegance (compactness)—an elegant program may take more steps to complete a computation than one less elegant. An example that uses Euclid's algorithm appears below.
Computers (and computors), models of computation: A computer (or human "computor") is a restricted type of machine, a "discrete deterministic mechanical device" that blindly follows its instructions. Melzak's and Lambek's primitive models reduced this notion to four elements: (i) discrete, distinguishable locations, (ii) discrete, indistinguishable counters (iii) an agent, and (iv) a list of instructions that are effective relative to the capability of the agent.
Minsky describes a more congenial variation of Lambek's "abacus" model in his "Very Simple Bases for Computability". Minsky's machine proceeds sequentially through its five (or six, depending on how one counts) instructions, unless either a conditional IF–THEN GOTO or an unconditional GOTO changes program flow out of sequence. Besides HALT, Minsky's machine includes three assignment (replacement, substitution) operations: ZERO (e.g. the contents of location replaced by 0: L ← 0), SUCCESSOR (e.g. L ← L+1), and DECREMENT (e.g. L ← L − 1). Rarely must a programmer write "code" with such a limited instruction set. But Minsky shows (as do Melzak and Lambek) that his machine is Turing complete with only four general types of instructions: conditional GOTO, unconditional GOTO, assignment/replacement/substitution, and HALT.
Simulation of an algorithm: computer (computor) language: Knuth advises the reader that "the best way to learn an algorithm is to try it... immediately take pen and paper and work through an example". But what about a simulation or execution of the real thing? The programmer must translate the algorithm into a language that the simulator/computer/computor can effectively execute. Stone gives an example of this: when computing the roots of a quadratic equation the computor must know how to take a square root. If they don't, then the algorithm, to be effective, must provide a set of rules for extracting a square root.
This means that the programmer must know a "language" that is effective relative to the target computing agent (computer/computor).
But what model should be used for the simulation? Van Emde Boas observes "even if we base complexity theory on abstract instead of concrete machines, arbitrariness of the choice of a model remains. It is at this point that the notion of simulation enters". When speed is being measured, the instruction set matters. For example, the subprogram in Euclid's algorithm to compute the remainder would execute much faster if the programmer had a "modulus" instruction available rather than just subtraction (or worse: just Minsky's "decrement").
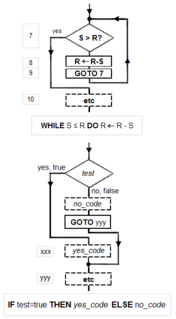
Structured programming, canonical structures: Per the Church–Turing thesis, any algorithm can be computed by a model known to be Turing complete, and per Minsky's demonstrations, Turing completeness requires only four instruction types—conditional GOTO, unconditional GOTO, assignment, HALT. Kemeny and Kurtz observe that, while "undisciplined" use of unconditional GOTOs and conditional IF-THEN GOTOs can result in "spaghetti code", a programmer can write structured programs using only these instructions; on the other hand "it is also possible, and not too hard, to write badly structured programs in a structured language". Tausworthe augments the three Böhm-Jacopini canonical structures: SEQUENCE, IF-THEN-ELSE, and WHILE-DO, with two more: DO-WHILE and CASE. An additional benefit of a structured program is that it lends itself to proofs of correctness using mathematical induction.
Canonical flowchart symbols: The graphical aide called a flowchart offers a way to describe and document an algorithm (and a computer program of one). Like program flow of a Minsky machine, a flowchart always starts at the top of a page and proceeds down. Its primary symbols are only four: the directed arrow showing program flow, the rectangle (SEQUENCE, GOTO), the diamond (IF-THEN-ELSE), and the dot (OR-tie). The Böhm–Jacopini canonical structures are made of these primitive shapes. Sub-structures can "nest" in rectangles, but only if a single exit occurs from the superstructure. The symbols, and their use to build the canonical structures, are shown in the diagram.
Examples
Algorithm example

One of the simplest algorithms is to find the largest number in a list of numbers of random order. Finding the solution requires looking at every number in the list. From this follows a simple algorithm, which can be stated in a high-level description English prose, as:
High-level description:
- If there are no numbers in the set then there is no highest number.
- Assume the first number in the set is the largest number in the set.
- For each remaining number in the set: if this number is larger than the current largest number, consider this number to be the largest number in the set.
- When there are no numbers left in the set to iterate over, consider the current largest number to be the largest number of the set.
(Quasi-)formal description: Written in prose but much closer to the high-level language of a computer program, the following is the more formal coding of the algorithm in pseudocode or pidgin code:
Algorithm LargestNumber Input: A list of numbers L. Output: The largest number in the list L.
if L.size = 0 return null
largest ← L[0]
for each item in L, do
if item > largest, then
largest ← item
return largest
- "←" denotes assignment. For instance, "largest ← item" means that the value of largest changes to the value of item.
- "return" terminates the algorithm and outputs the following value.
Euclid's algorithm
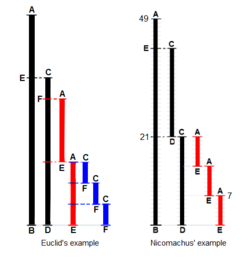
Euclid's algorithm to compute the greatest common divisor (GCD) to two numbers appears as Proposition II in Book VII ("Elementary Number Theory") of his Elements. Euclid poses the problem thus: "Given two numbers not prime to one another, to find their greatest common measure". He defines "A number [to be] a multitude composed of units": a counting number, a positive integer not including zero. To "measure" is to place a shorter measuring length s successively (q times) along longer length l until the remaining portion r is less than the shorter length s.In modern words, remainder r = l − q×s, q being the quotient, or remainder r is the "modulus", the integer-fractional part left over after the division.
For Euclid's method to succeed, the starting lengths must satisfy two requirements: (i) the lengths must not be zero, AND (ii) the subtraction must be “proper”; i.e., a test must guarantee that the smaller of the two numbers is subtracted from the larger (alternately, the two can be equal so their subtraction yields zero).
Euclid's original proof adds a third requirement: the two lengths must not be prime to one another. Euclid stipulated this so that he could construct a reductio ad absurdum proof that the two numbers' common measure is in fact the greatest. While Nicomachus' algorithm is the same as Euclid's, when the numbers are prime to one another, it yields the number "1" for their common measure. So, to be precise, the following is really Nicomachus' algorithm.

Computer language for Euclid's algorithm
Only a few instruction types are required to execute Euclid's algorithm—some logical tests (conditional GOTO), unconditional GOTO, assignment (replacement), and subtraction.
- A location is symbolized by upper case letter(s), e.g. S, A, etc.
- The varying quantity (number) in a location is written in lower case letter(s) and (usually) associated with the location's name. For example, location L at the start might contain the number l = 3009.
An inelegant program for Euclid's algorithm

The following algorithm is framed as Knuth's four-step version of Euclid's and Nicomachus', but, rather than using division to find the remainder, it uses successive subtractions of the shorter length s from the remaining length r until r is less than s. The high-level description, shown in boldface, is adapted from Knuth 1973:2–4:
INPUT:
1 [Into two locations L and S put the numbers l and s that represent the two lengths]: INPUT L, S 2 [Initialize R: make the remaining length r equal to the starting/initial/input length l]: R ← L
E0: [Ensure r ≥ s.]
3 [Ensure the smaller of the two numbers is in S and the larger in R]: IF R > S THEN the contents of L is the larger number so skip over the exchange-steps 4, 5 and 6: GOTO step 6 ELSE swap the contents of R and S. 4 L ← R (this first step is redundant, but is useful for later discussion). 5 R ← S 6 S ← L
E1: [Find remainder]: Until the remaining length r in R is less than the shorter length s in S, repeatedly subtract the measuring number s in S from the remaining length r in R.
7 IF S > R THEN done measuring so GOTO 10 ELSE measure again, 8 R ← R − S 9 [Remainder-loop]: GOTO 7.
E2: [Is the remainder zero?]: EITHER (i) the last measure was exact, the remainder in R is zero, and the program can halt, OR (ii) the algorithm must continue: the last measure left a remainder in R less than measuring number in S.
10 IF R = 0 THEN
done so
GOTO step 15
ELSE
CONTINUE TO step 11,
E3: [Interchange s and r]: The nut of Euclid's algorithm. Use remainder r to measure what was previously smaller number s; L serves as a temporary location.
11 L ← R 12 R ← S 13 S ← L 14 [Repeat the measuring process]: GOTO 7
OUTPUT:
15 [Done. S contains the greatest common divisor]:
PRINT S
DONE:
16 HALT, END, STOP.
An elegant program for Euclid's algorithm
The following version of Euclid's algorithm requires only six core instructions to do what thirteen are required to do by "Inelegant"; worse, "Inelegant" requires more types of instructions. The flowchart of "Elegant" can be found at the top of this article. In the (unstructured) Basic language, the steps are numbered, and the instruction
LET [] = [] is the assignment instruction symbolized by ←.5 REM Euclid's algorithm for greatest common divisor
6 PRINT "Type two integers greater than 0"
10 INPUT A,B
20 IF B=0 THEN GOTO 80
30 IF A > B THEN GOTO 60
40 LET B=B-A
50 GOTO 20
60 LET A=A-B
70 GOTO 20
80 PRINT A
90 END
The following version can be used with Object Oriented languages:
// Euclid's algorithm for greatest common divisor
integer euclidAlgorithm (int A, int B){
A=Math.abs(A);
B=Math.abs(B);
while (B!=0){
if (A>B) A=A-B;
else B=B-A;
}
return A;
}
How "Elegant" works: In place of an outer "Euclid loop", "Elegant" shifts back and forth between two "co-loops", an A > B loop that computes A ← A − B, and a B ≤ A loop that computes B ← B − A. This works because, when at last the minuend M is less than or equal to the subtrahend S ( Difference = Minuend − Subtrahend), the minuend can become s (the new measuring length) and the subtrahend can become the new r (the length to be measured); in other words the "sense" of the subtraction reverses.
Testing the Euclid algorithms
Does an algorithm do what its author wants it to do? A few test cases usually suffice to confirm core functionality. One source uses 3009 and 884. Knuth suggested 40902, 24140. Another interesting case is the two relatively prime numbers 14157 and 5950.
But exceptional cases must be identified and tested. Will "Inelegant" perform properly when R > S, S > R, R = S? Ditto for "Elegant": B > A, A > B, A = B? (Yes to all). What happens when one number is zero, both numbers are zero? ("Inelegant" computes forever in all cases; "Elegant" computes forever when A = 0.) What happens if negative numbers are entered? Fractional numbers? If the input numbers, i.e. the domain of the function computed by the algorithm/program, is to include only positive integers including zero, then the failures at zero indicate that the algorithm (and the program that instantiates it) is a partial function rather than a total function. A notable failure due to exceptions is the Ariane 5 Flight 501 rocket failure (June 4, 1996).
Proof of program correctness by use of mathematical induction: Knuth demonstrates the application of mathematical induction to an "extended" version of Euclid's algorithm, and he proposes "a general method applicable to proving the validity of any algorithm". Tausworthe proposes that a measure of the complexity of a program be the length of its correctness proof.
Measuring and improving the Euclid algorithms
Elegance (compactness) versus goodness (speed): With only six core instructions, "Elegant" is the clear winner, compared to "Inelegant" at thirteen instructions. However, "Inelegant" is faster(it arrives at HALT in fewer steps). Algorithm analysis indicates why this is the case: "Elegant" does two conditional tests in every subtraction loop, whereas "Inelegant" only does one. As the algorithm (usually) requires many loop-throughs, on average much time is wasted doing a "B = 0?" test that is needed only after the remainder is computed.
Can the algorithms be improved?: Once the programmer judges a program "fit" and "effective"—that is, it computes the function intended by its author—then the question becomes, can it be improved?
The compactness of "Inelegant" can be improved by the elimination of five steps. But Chaitin proved that compacting an algorithm cannot be automated by a generalized algorithm; rather, it can only be done heuristically; i.e., by exhaustive search (examples to be found at Busy beaver), trial and error, cleverness, insight, application of inductive reasoning, etc. Observe that steps 4, 5 and 6 are repeated in steps 11, 12 and 13. Comparison with "Elegant" provides a hint that these steps, together with steps 2 and 3, can be eliminated. This reduces the number of core instructions from thirteen to eight, which makes it "more elegant" than "Elegant", at nine steps.
The speed of "Elegant" can be improved by moving the "B=0?" test outside of the two subtraction loops. This change calls for the addition of three instructions (B = 0?, A = 0?, GOTO). Now "Elegant" computes the example-numbers faster; whether this is always the case for any given A, B and R, S would require a detailed analysis.
Algorithmic analysis
It is frequently important to know how much of a particular resource (such as time or storage) is theoretically required for a given algorithm. Methods have been developed for the analysis of algorithms to obtain such quantitative answers (estimates); for example, the sorting algorithm above has a time requirement of O(n), using the big O notation with n as the length of the list. At all times the algorithm only needs to remember two values: the largest number found so far, and its current position in the input list. Therefore, it is said to have a space requirement of O(1), if the space required to store the input numbers is not counted, or O(n) if it is counted.
Different algorithms may complete the same task with a different set of instructions in less or more time, space, or 'effort' than others. For example, a binary search algorithm (with cost O(log n) ) outperforms a sequential search (cost O(n) ) when used for table lookups on sorted lists or arrays.
Formal versus empirical
The analysis and study of algorithms is a discipline of computer science, and is often practiced abstractly without the use of a specific programming language or implementation. In this sense, algorithm analysis resembles other mathematical disciplines in that it focuses on the underlying properties of the algorithm and not on the specifics of any particular implementation. Usually pseudocode is used for analysis as it is the simplest and most general representation. However, ultimately, most algorithms are usually implemented on particular hardware / software platforms and their algorithmic efficiency is eventually put to the test using real code. For the solution of a "one off" problem, the efficiency of a particular algorithm may not have significant consequences (unless n is extremely large) but for algorithms designed for fast interactive, commercial or long life scientific usage it may be critical. Scaling from small n to large n frequently exposes inefficient algorithms that are otherwise benign.
Empirical testing is useful because it may uncover unexpected interactions that affect performance. Benchmarks may be used to compare before/after potential improvements to an algorithm after program optimization. Empirical tests cannot replace formal analysis, though, and are not trivial to perform in a fair manner.
Execution efficiency
To illustrate the potential improvements possible even in well established algorithms, a recent significant innovation, relating to FFT algorithms (used heavily in the field of image processing), can decrease processing time up to 1,000 times for applications like medical imaging. In general, speed improvements depend on special properties of the problem, which are very common in practical applications. Speedups of this magnitude enable computing devices that make extensive use of image processing (like digital cameras and medical equipment) to consume less power.
Classification
There are various ways to classify algorithms, each with its own merits.
By implementation
One way to classify algorithms is by implementation means.
- Recursion
- A recursive algorithm is one that invokes (makes reference to) itself repeatedly until a certain condition (also known as termination condition) matches, which is a method common to functional programming. Iterative algorithms use repetitive constructs like loops and sometimes additional data structures like stacks to solve the given problems. Some problems are naturally suited for one implementation or the other. For example, towers of Hanoi is well understood using recursive implementation. Every recursive version has an equivalent (but possibly more or less complex) iterative version, and vice versa.
- Logical
- An algorithm may be viewed as controlled logical deduction. This notion may be expressed as: Algorithm = logic + control. The logic component expresses the axioms that may be used in the computation and the control component determines the way in which deduction is applied to the axioms. This is the basis for the logic programming paradigm. In pure logic programming languages the control component is fixed and algorithms are specified by supplying only the logic component. The appeal of this approach is the elegant semantics: a change in the axioms has a well-defined change in the algorithm.
- Serial, parallel or distributed
- Algorithms are usually discussed with the assumption that computers execute one instruction of an algorithm at a time. Those computers are sometimes called serial computers. An algorithm designed for such an environment is called a serial algorithm, as opposed to parallel algorithms or distributed algorithms. Parallel algorithms take advantage of computer architectures where several processors can work on a problem at the same time, whereas distributed algorithms utilize multiple machines connected with a computer network. Parallel or distributed algorithms divide the problem into more symmetrical or asymmetrical subproblems and collect the results back together. The resource consumption in such algorithms is not only processor cycles on each processor but also the communication overhead between the processors. Some sorting algorithms can be parallelized efficiently, but their communication overhead is expensive. Iterative algorithms are generally parallelizable. Some problems have no parallel algorithms, and are called inherently serial problems.
- Deterministic or non-deterministic
- Deterministic algorithms solve the problem with exact decision at every step of the algorithm whereas non-deterministic algorithms solve problems via guessing although typical guesses are made more accurate through the use of heuristics.
- Exact or approximate
- While many algorithms reach an exact solution, approximation algorithms seek an approximation that is closer to the true solution. Approximation can be reached by either using a deterministic or a random strategy. Such algorithms have practical value for many hard problems. One of the examples of an approximate algorithm is the Knapsack problem. The Knapsack problem is a problem where there is a set of given items. The goal of the problem is to pack the knapsack to get the maximum total value. Each item has some weight and some value. Total weight that we can carry is no more than some fixed number X. So, we must consider weights of items as well as their value.
- Quantum algorithm
- They run on a realistic model of quantum computation. The term is usually used for those algorithms which seem inherently quantum, or use some essential feature of quantum computation such as quantum superposition or quantum entanglement.
By design paradigm
Another way of classifying algorithms is by their design methodology or paradigm. There is a certain number of paradigms, each different from the other. Furthermore, each of these categories include many different types of algorithms. Some common paradigms are:
- Brute-force or exhaustive search
- This is the naive method of trying every possible solution to see which is best.
- Divide and conquer
- A divide and conquer algorithm repeatedly reduces an instance of a problem to one or more smaller instances of the same problem (usually recursively) until the instances are small enough to solve easily. One such example of divide and conquer is merge sorting. Sorting can be done on each segment of data after dividing data into segments and sorting of entire data can be obtained in the conquer phase by merging the segments. A simpler variant of divide and conquer is called a decrease and conquer algorithm, that solves an identical subproblem and uses the solution of this subproblem to solve the bigger problem. Divide and conquer divides the problem into multiple subproblems and so the conquer stage is more complex than decrease and conquer algorithms. An example of decrease and conquer algorithm is the binary search algorithm.
- Search and enumeration
- Many problems (such as playing chess) can be modeled as problems on graphs. A graph exploration algorithm specifies rules for moving around a graph and is useful for such problems. This category also includes search algorithms, branch and bound enumeration and backtracking.
- Randomized algorithm
- Such algorithms make some choices randomly (or pseudo-randomly). They can be very useful in finding approximate solutions for problems where finding exact solutions can be impractical (see heuristic method below). For some of these problems, it is known that the fastest approximations must involve some randomness. Whether randomized algorithms with polynomial time complexity can be the fastest algorithms for some problems is an open question known as the P versus NP problem. There are two large classes of such algorithms:
- Monte Carlo algorithms return a correct answer with high-probability. E.g. RP is the subclass of these that run in polynomial time.
- Las Vegas algorithms always return the correct answer, but their running time is only probabilistically bound, e.g. ZPP.
- Reduction of complexity
- This technique involves solving a difficult problem by transforming it into a better known problem for which we have (hopefully) asymptotically optimal algorithms. The goal is to find a reducing algorithm whose complexity is not dominated by the resulting reduced algorithm's. For example, one selection algorithm for finding the median in an unsorted list involves first sorting the list (the expensive portion) and then pulling out the middle element in the sorted list (the cheap portion). This technique is also known as transform and conquer.
- Back tracking
- In this approach multiple solutions are built incrementally and abandoned when it is determined that they cannot lead to a valid full solution.
Optimization problems
For optimization problems there is a more specific classification of algorithms; an algorithm for such problems may fall into one or more of the general categories described above as well as into one of the following:
- Linear programming
- When searching for optimal solutions to a linear function bound to linear equality and inequality constraints, the constraints of the problem can be used directly in producing the optimal solutions. There are algorithms that can solve any problem in this category, such as the popular simplex algorithm. Problems that can be solved with linear programming include the maximum flow problem for directed graphs. If a problem additionally requires that one or more of the unknowns must be an integer then it is classified in integer programming. A linear programming algorithm can solve such a problem if it can be proved that all restrictions for integer values are superficial, i.e., the solutions satisfy these restrictions anyway. In the general case, a specialized algorithm or an algorithm that finds approximate solutions is used, depending on the difficulty of the problem.
- Dynamic programming
- When a problem shows optimal substructures – meaning the optimal solution to a problem can be constructed from optimal solutions to subproblems – and overlapping subproblems, meaning the same subproblems are used to solve many different problem instances, a quicker approach called dynamic programming avoids recomputing solutions that have already been computed. For example, Floyd–Warshall algorithm, the shortest path to a goal from a vertex in a weighted graph can be found by using the shortest path to the goal from all adjacent vertices. Dynamic programming and memoization go together. The main difference between dynamic programming and divide and conquer is that subproblems are more or less independent in divide and conquer, whereas subproblems overlap in dynamic programming. The difference between dynamic programming and straightforward recursion is in caching or memoization of recursive calls. When subproblems are independent and there is no repetition, memoization does not help; hence dynamic programming is not a solution for all complex problems. By using memoization or maintaining a table of subproblems already solved, dynamic programming reduces the exponential nature of many problems to polynomial complexity.
- The greedy method
- A greedy algorithm is similar to a dynamic programming algorithm in that it works by examining substructures, in this case not of the problem but of a given solution. Such algorithms start with some solution, which may be given or have been constructed in some way, and improve it by making small modifications. For some problems they can find the optimal solution while for others they stop at local optima, that is, at solutions that cannot be improved by the algorithm but are not optimum. The most popular use of greedy algorithms is for finding the minimal spanning tree where finding the optimal solution is possible with this method. Huffman Tree, Kruskal, Prim, Sollin are greedy algorithms that can solve this optimization problem.
- The heuristic method
- In optimization problems, heuristic algorithms can be used to find a solution close to the optimal solution in cases where finding the optimal solution is impractical. These algorithms work by getting closer and closer to the optimal solution as they progress. In principle, if run for an infinite amount of time, they will find the optimal solution. Their merit is that they can find a solution very close to the optimal solution in a relatively short time. Such algorithms include local search, tabu search, simulated annealing, and genetic algorithms. Some of them, like simulated annealing, are non-deterministic algorithms while others, like tabu search, are deterministic. When a bound on the error of the non-optimal solution is known, the algorithm is further categorized as an approximation algorithm.
By field of study
Every field of science has its own problems and needs efficient algorithms. Related problems in one field are often studied together. Some example classes are search algorithms, sorting algorithms, merge algorithms, numerical algorithms, graph algorithms, string algorithms, computational geometric algorithms, combinatorial algorithms, medical algorithms, machine learning, cryptography, data compression algorithms and parsing techniques.
Fields tend to overlap with each other, and algorithm advances in one field may improve those of other, sometimes completely unrelated, fields. For example, dynamic programming was invented for optimization of resource consumption in industry, but is now used in solving a broad range of problems in many fields.
By complexity
Algorithms can be classified by the amount of time they need to complete compared to their input size:
- Constant time: if the time needed by the algorithm is the same, regardless of the input size. E.g. an access to an array element.
- Linear time: if the time is proportional to the input size. E.g. the traverse of a list.
- Logarithmic time: if the time is a logarithmic function of the input size. E.g. binary search algorithm.
- Polynomial time: if the time is a power of the input size. E.g. the bubble sort algorithm has quadratic time complexity.
- Exponential time: if the time is an exponential function of the input size. E.g. Brute-force search.
Some problems may have multiple algorithms of differing complexity, while other problems might have no algorithms or no known efficient algorithms. There are also mappings from some problems to other problems. Owing to this, it was found to be more suitable to classify the problems themselves instead of the algorithms into equivalence classes based on the complexity of the best possible algorithms for them.
Continuous algorithms
The adjective "continuous" when applied to the word "algorithm" can mean:
- An algorithm operating on data that represents continuous quantities, even though this data is represented by discrete approximations—such algorithms are studied in numerical analysis; or
- An algorithm in the form of a differential equation that operates continuously on the data, running on an analog computer.
Legal issues
Algorithms, by themselves, are not usually patentable. In the United States, a claim consisting solely of simple manipulations of abstract concepts, numbers, or signals does not constitute "processes" (USPTO 2006), and hence algorithms are not patentable (as in Gottschalk v. Benson). However, practical applications of algorithms are sometimes patentable. For example, in Diamond v. Diehr, the application of a simple feedback algorithm to aid in the curing of synthetic rubber was deemed patentable. The patenting of software is highly controversial, and there are highly criticized patents involving algorithms, especially data compression algorithms, such as Unisys' LZW patent.
Additionally, some cryptographic algorithms have export restrictions (see export of cryptography).
Researcher, Andrew Tutt, argues that algorithms should be overseen by a specialist regulatory agency, similar to FDA. His academic work emphasizes that the rise of increasingly complex algorithms calls for the need to think about the effects of algorithms today. Due to the nature and complexity of algorithms, it will prove to be difficult to hold algorithms accountable under criminal law. Tutt recognizes that while some algorithms will be beneficial to help meet technological demand, others should not be used or sold if they fail to meet safety requirements. Thus, for Tutt, algorithms will require "closer forms of federal uniformity, expert judgment, political independence, and pre-market review to prevent the introduction of unacceptably dangerous algorithms into the market". The issue of algorithmic accountability (the responsibility of algorithm designers to provide evidence of potential or realised harms) is of particular relevance in the field of dynamic and non-linearly programmed systems, e.g. artificial neural networks, deep learning, and genetic algorithms (see Explainable AI).
History: Development of the notion of "algorithm"
Ancient Near East
Algorithms were used in ancient Greece. Two examples are the Sieve of Eratosthenes, which was described in Introduction to Arithmetic by Nicomachus, and the Euclidean algorithm, which was first described in Euclid's Elements (c. 300 BC). Babylonian clay tablets describe and employ algorithmic procedures to compute the time and place of significant astronomical events.
Discrete and distinguishable symbols
Tally-marks: To keep track of their flocks, their sacks of grain and their money the ancients used tallying: accumulating stones or marks scratched on sticks, or making discrete symbols in clay. Through the Babylonian and Egyptian use of marks and symbols, eventually Roman numerals and the abacus evolved (Dilson, p. 16–41). Tally marks appear prominently in unary numeral system arithmetic used in Turing machine and Post–Turing machine computations.
Manipulation of symbols as "place holders" for numbers: algebra
The work of the ancient Greek geometers (Euclidean algorithm), the Indian mathematician Brahmagupta, and the Persian mathematician Al-Khwarizmi (from whose name the terms "algorism" and "algorithm" are derived), and Western European mathematicians culminated in Leibniz's notion of the calculus ratiocinator (ca 1680):
Mechanical contrivances with discrete states
The clock: Bolter credits the invention of the weight-driven clock as "The key invention [of Europe in the Middle Ages]", in particular the verge escapement that provides us with the tick and tock of a mechanical clock. "The accurate automatic machine" led immediately to "mechanical automata" beginning in the 13th century and finally to "computational machines"—the difference engine and analytical engines of Charles Babbage and Countess Ada Lovelace, mid-19th century. Lovelace is credited with the first creation of an algorithm intended for processing on a computer – Babbage's analytical engine, the first device considered a real Turing-complete computer instead of just a calculator – and is sometimes called "history's first programmer" as a result, though a full implementation of Babbage's second device would not be realized until decades after her lifetime.
Logical machines 1870—Stanley Jevons' "logical abacus" and "logical machine": The technical problem was to reduce Boolean equations when presented in a form similar to what are now known as Karnaugh maps. Jevons (1880) describes first a simple "abacus" of "slips of wood furnished with pins, contrived so that any part or class of the [logical] combinations can be picked out mechanically... More recently however I have reduced the system to a completely mechanical form, and have thus embodied the whole of the indirect process of inference in what may be called a Logical Machine" His machine came equipped with "certain moveable wooden rods" and "at the foot are 21 keys like those of a piano [etc]...". With this machine he could analyze a "syllogism or any other simple logical argument".
This machine he displayed in 1870 before the Fellows of the Royal Society. Another logician John Venn, however, in his 1881 Symbolic Logic, turned a jaundiced eye to this effort: "I have no high estimate myself of the interest or importance of what are sometimes called logical machines... it does not seem to me that any contrivances at present known or likely to be discovered really deserve the name of logical machines"; see more at Algorithm characterizations. But not to be outdone he too presented "a plan somewhat analogous, I apprehend, to Prof. Jevon's abacus ... [And] [a]gain, corresponding to Prof. Jevons's logical machine, the following contrivance may be described. I prefer to call it merely a logical-diagram machine... but I suppose that it could do very completely all that can be rationally expected of any logical machine".
Jacquard loom, Hollerith punch cards, telegraphy and telephony—the electromechanical relay: Bell and Newell (1971) indicate that the Jacquard loom (1801), precursor to Hollerith cards(punch cards, 1887), and "telephone switching technologies" were the roots of a tree leading to the development of the first computers. By the mid-19th century the telegraph, the precursor of the telephone, was in use throughout the world, its discrete and distinguishable encoding of letters as "dots and dashes" a common sound. By the late 19th century the ticker tape (ca 1870s) was in use, as was the use of Hollerith cards in the 1890 U.S. census. Then came the teleprinter (ca. 1910) with its punched-paper use of Baudot code on tape.
Telephone-switching networks of electromechanical relays (invented 1835) was behind the work of George Stibitz (1937), the inventor of the digital adding device. As he worked in Bell Laboratories, he observed the "burdensome' use of mechanical calculators with gears. "He went home one evening in 1937 intending to test his idea... When the tinkering was over, Stibitz had constructed a binary adding device".
Davis (2000) observes the particular importance of the electromechanical relay (with its two "binary states" open and closed):
- It was only with the development, beginning in the 1930s, of electromechanical calculators using electrical relays, that machines were built having the scope Babbage had envisioned."
Mathematics during the 19th century up to the mid-20th century
Symbols and rules: In rapid succession the mathematics of George Boole (1847, 1854), Gottlob Frege (1879), and Giuseppe Peano (1888–1889) reduced arithmetic to a sequence of symbols manipulated by rules. Peano's The principles of arithmetic, presented by a new method (1888) was "the first attempt at an axiomatization of mathematics in a symbolic language".
But Heijenoort gives Frege (1879) this kudos: Frege's is "perhaps the most important single work ever written in logic.... in which we see a " 'formula language', that is a lingua characterica, a language written with special symbols, "for pure thought", that is, free from rhetorical embellishments... constructed from specific symbols that are manipulated according to definite rules". The work of Frege was further simplified and amplified by Alfred North Whitehead and Bertrand Russell in their Principia Mathematica (1910–1913).
The paradoxes: At the same time a number of disturbing paradoxes appeared in the literature, in particular the Burali-Forti paradox (1897), the Russell paradox (1902–03), and the Richard Paradox. The resultant considerations led to Kurt Gödel's paper (1931)—he specifically cites the paradox of the liar—that completely reduces rules of recursion to numbers.
Effective calculability: In an effort to solve the Entscheidungsproblem defined precisely by Hilbert in 1928, mathematicians first set about to define what was meant by an "effective method" or "effective calculation" or "effective calculability" (i.e., a calculation that would succeed). In rapid succession the following appeared: Alonzo Church, Stephen Kleene and J. B. Rosser's λ-calculus a finely honed definition of "general recursion" from the work of Gödel acting on suggestions of Jacques Herbrand (cf. Gödel's Princeton lectures of 1934) and subsequent simplifications by Kleene. Church's proof that the Entscheidungsproblem was unsolvable, Emil Post's definition of effective calculability as a worker mindlessly following a list of instructions to move left or right through a sequence of rooms and while there either mark or erase a paper or observe the paper and make a yes-no decision about the next instruction. Alan Turing's proof of that the Entscheidungsproblem was unsolvable by use of his "a- [automatic-] machine"—in effect almost identical to Post's "formulation", J. Barkley Rosser's definition of "effective method" in terms of "a machine". S. C. Kleene's proposal of a precursor to "Church thesis" that he called "Thesis I", and a few years later Kleene's renaming his Thesis "Church's Thesis" and proposing "Turing's Thesis".
Emil Post (1936) and Alan Turing (1936–37, 1939)
Here is a remarkable coincidence of two men not knowing each other but describing a process of men-as-computers working on computations—and they yield virtually identical definitions.
Emil Post (1936) described the actions of a "computer" (human being) as follows:
- "...two concepts are involved: that of a symbol space in which the work leading from problem to answer is to be carried out, and a fixed unalterable set of directions.
His symbol space would be
- "a two way infinite sequence of spaces or boxes... The problem solver or worker is to move and work in this symbol space, being capable of being in, and operating in but one box at a time.... a box is to admit of but two possible conditions, i.e., being empty or unmarked, and having a single mark in it, say a vertical stroke.
- "One box is to be singled out and called the starting point....a specific problem is to be given in symbolic form by a finite number of boxes [i.e., INPUT] being marked with a stroke. Likewise the answer [i.e., OUTPUT] is to be given in symbolic form by such a configuration of marked boxes....
- "A set of directions applicable to a general problem sets up a deterministic process when applied to each specific problem. This process terminates only when it comes to the direction of type (C ) [i.e., STOP]". See more at Post–Turing machine

Alan Turing's work preceded that of Stibitz (1937); it is unknown whether Stibitz knew of the work of Turing. Turing's biographer believed that Turing's use of a typewriter-like model derived from a youthful interest: "Alan had dreamt of inventing typewriters as a boy; Mrs. Turing had a typewriter; and he could well have begun by asking himself what was meant by calling a typewriter 'mechanical'". Given the prevalence of Morse code and telegraphy, ticker tape machines, and teletypewriters we might conjecture that all were influences.
Turing—his model of computation is now called a Turing machine—begins, as did Post, with an analysis of a human computer that he whittles down to a simple set of basic motions and "states of mind". But he continues a step further and creates a machine as a model of computation of numbers.
- "Computing is normally done by writing certain symbols on paper. We may suppose this paper is divided into squares like a child's arithmetic book...I assume then that the computation is carried out on one-dimensional paper, i.e., on a tape divided into squares. I shall also suppose that the number of symbols which may be printed is finite...
- "The behaviour of the computer at any moment is determined by the symbols which he is observing, and his "state of mind" at that moment. We may suppose that there is a bound B to the number of symbols or squares which the computer can observe at one moment. If he wishes to observe more, he must use successive observations. We will also suppose that the number of states of mind which need be taken into account is finite...
- "Let us imagine that the operations performed by the computer to be split up into 'simple operations' which are so elementary that it is not easy to imagine them further divided."
Turing's reduction yields the following:
- "The simple operations must therefore include:
- "(a) Changes of the symbol on one of the observed squares
- "(b) Changes of one of the squares observed to another square within L squares of one of the previously observed squares.
"It may be that some of these change necessarily invoke a change of state of mind. The most general single operation must therefore be taken to be one of the following:
-
- "(A) A possible change (a) of symbol together with a possible change of state of mind.
- "(B) A possible change (b) of observed squares, together with a possible change of state of mind"
- "We may now construct a machine to do the work of this computer."
A few years later, Turing expanded his analysis (thesis, definition) with this forceful expression of it:
- "A function is said to be "effectively calculable" if its values can be found by some purely mechanical process. Though it is fairly easy to get an intuitive grasp of this idea, it is nevertheless desirable to have some more definite, mathematical expressible definition... [he discusses the history of the definition pretty much as presented above with respect to Gödel, Herbrand, Kleene, Church, Turing and Post]... We may take this statement literally, understanding by a purely mechanical process one which could be carried out by a machine. It is possible to give a mathematical description, in a certain normal form, of the structures of these machines. The development of these ideas leads to the author's definition of a computable function, and to an identification of computability † with effective calculability....
- "† We shall use the expression "computable function" to mean a function calculable by a machine, and we let "effectively calculable" refer to the intuitive idea without particular identification with any one of these definitions".
J. B. Rosser (1939) and S. C. Kleene (1943)
J. Barkley Rosser defined an 'effective [mathematical] method' in the following manner (italicization added):
- "'Effective method' is used here in the rather special sense of a method each step of which is precisely determined and which is certain to produce the answer in a finite number of steps. With this special meaning, three different precise definitions have been given to date. [his footnote #5; see discussion immediately below]. The simplest of these to state (due to Post and Turing) says essentially that an effective method of solving certain sets of problems exists if one can build a machine which will then solve any problem of the set with no human intervention beyond inserting the question and (later) reading the answer. All three definitions are equivalent, so it doesn't matter which one is used. Moreover, the fact that all three are equivalent is a very strong argument for the correctness of any one." (Rosser 1939:225–6)
Rosser's footnote No. 5 references the work of (1) Church and Kleene and their definition of λ-definability, in particular Church's use of it in his An Unsolvable Problem of Elementary Number Theory (1936); (2) Herbrand and Gödel and their use of recursion in particular Gödel's use in his famous paper On Formally Undecidable Propositions of Principia Mathematica and Related Systems I (1931); and (3) Post (1936) and Turing (1936–37) in their mechanism-models of computation.
Stephen C. Kleene defined as his now-famous "Thesis I" known as the Church–Turing thesis. But he did this in the following context (boldface in original):
- "12. Algorithmic theories... In setting up a complete algorithmic theory, what we do is to describe a procedure, performable for each set of values of the independent variables, which procedure necessarily terminates and in such manner that from the outcome we can read a definite answer, "yes" or "no," to the question, "is the predicate value true?"" (Kleene 1943:273)
History after 1950
A number of efforts have been directed toward further refinement of the definition of "algorithm", and activity is on-going because of issues surrounding, in particular, foundations of mathematics (especially the Church–Turing thesis) and philosophy of mind (especially arguments about artificial intelligence). For more, see Algorithm characterizations.